OpenMP Offloading: Compute Constructs¶
Script
- "In this section, we’ll delve into the compute constructs of OpenMP Offloading, which empower developers to execute parallel code seamlessly across CPUs and GPUs. These constructs provide fine-grained control over data handling and computational hierarchies, ensuring that performance is optimized for diverse hardware configurations. Key constructs, such as target, teams, distribute, parallel, and simd, offer flexibility to tailor execution for specific workloads."
- "The target construct serves as the cornerstone of OpenMP Offloading, enabling code execution on accelerators like GPUs. It establishes a device context where both data and code are mapped to the device’s environment. When combined with other constructs, such as teams and parallel, it facilitates efficient parallel execution, leveraging the full computational power of heterogeneous systems."
- "The target data construct, on the other hand, focuses on creating a persistent data environment on the device. This means that data remains available on the device across multiple code regions, reducing the overhead caused by frequent data transfers. This is particularly advantageous in complex calculations where data reuse is common."
- "The teams construct divides the workload among multiple teams on the device, with each team comprising a set of threads. This hierarchical organization mirrors the architecture of GPUs, which excel at managing large numbers of threads within team structures. By employing this construct, developers can efficiently scale their applications to utilize the available resources on the device."
- "The distribute construct complements the teams construct by assigning loop iterations to team leaders. Each team leader manages a portion of the workload, ensuring that large datasets or computationally intensive tasks are divided effectively. This construct is especially useful when handling massive workloads that demand the distributed capabilities of GPUs."
- "OpenMP Offloading constructs can be combined to achieve maximum performance on heterogeneous devices. For instance, the combination of target teams distribute parallel for simd enables code offloading to the device, distributes the work across teams and threads, and incorporates SIMD vectorization. This configuration optimizes computation by leveraging device parallelism at multiple levels, from teams and threads to vectorized SIMD lanes."
- "This table highlights the syntax for commonly used OpenMP Offloading constructs, providing a quick reference for their usage and purpose. For example, the target teams distribute parallel for simd construct combines directives for offloading, work distribution, thread parallelization, and SIMD execution, making it a comprehensive solution for high-performance computing."
- "Loop and parallel constructs, such as target parallel and target teams loop, offer a variety of options for executing loop iterations and parallel blocks on the device. These constructs enable threads within teams to process iterations concurrently, significantly accelerating loop-based computations."
- "Adding SIMD constructs, such as target simd and parallel for simd, enhances throughput by enabling vectorized execution. Combining these directives with team and parallel constructs provides an ideal framework for high-performance applications on SIMD-enabled hardware, achieving optimal utilization of vector units."
- "OpenMP Offloading constructs, from target to simd, offer developers a robust and flexible set of tools for high-level parallel programming. By thoughtfully combining these constructs, developers can create configurations that maximize performance across heterogeneous devices, paving the way for efficient and scalable solutions in modern computing."
This section provides an in-depth overview of OpenMP Offloading compute constructs, which enable parallel execution across CPUs and accelerators (e.g., GPUs). These constructs offer flexible, high-level parallelism and data mapping options, allowing fine-grained control over computation and data handling across devices. Key OpenMP Offloading constructs include target, target data, teams, distribute, and various combinations to maximize performance.
Key Compute Constructs in OpenMP Offloading¶
Target Construct¶
The target construct transfers data and code execution to the device (e.g., GPU). By using target, variables are mapped to the device’s data environment, and the enclosed code runs on that device.
-
C/C++:
#pragma omp target [clauses] -
Fortran:
!$omp target [clauses]
The target construct is versatile, serving as the foundation for most offloading constructs by establishing a device context. It can work with other constructs like parallel, teams, and simd to optimize computation.
Target data Construct¶
The target data construct defines a device data environment for a specified region, allowing data to reside on the device throughout the construct’s scope.
-
Usage: Used to map data to the device without running computation directly, which can reduce the need for frequent data transfers.
-
C/C++:
#pragma omp target data [clauses] - Fortran:
!$omp target data [clauses]
Teams Construct¶
The teams construct creates a "league" of teams on the target device, where each team has a specified number of threads. Within each team, an initial thread executes the region code. The number of teams and threads per team can be customized with clauses like num_teams and thread_limit.
-
Purpose: Optimizes parallelism on devices with hierarchical thread structures (e.g., GPUs).
-
C/C++:
#pragma omp target teams [clauses] - Fortran:
!$omp target teams [clauses]
Each team operates independently, executing its portion of the workload. This construct is effective for distributing workload across teams of threads, which can later be combined with distribute or parallel for fine-grained control.
Distribute Construct¶
The distribute construct divides a loop’s iterations among the master threads of each team, allowing each team to execute a subset of the iterations.
-
Usage: Often used with
targetandteamsto allocate work across teams, which is useful in cases with large workloads. -
C/C++:
#pragma omp target teams distribute [clauses] - Fortran:
!$omp target teams distribute [clauses]
The distribute construct optimally handles loops by distributing work across team leaders. This is an essential construct in GPU programming, where loop iterations are distributed across teams.
Combining Directives for Enhanced Performance¶
OpenMP Offloading constructs can be combined to increase performance, with each combination catering to different parallelization needs. For instance:
target teams: Offloads code to the device and distributes it among teams.target teams distribute: Distributes loop iterations across the team leaders on the device.target teams distribute parallel for: Offloads and distributes iterations in parallel across threads within teams.target teams distribute parallel for simd: Adds vectorization for enhanced performance, ensuring work is parallelized across teams, threads, and SIMD (single instruction, multiple data) lanes.
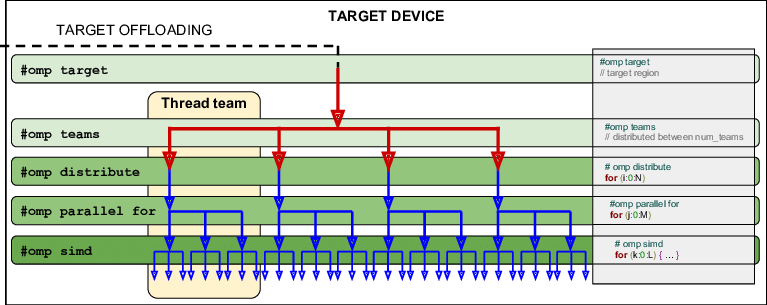
Hierarchy of OpenMP Offloading Constructs
Detailed Syntax and Examples for Common Constructs¶
This table introduces the basic constructs for offloading code and data from the host (CPU) to a device (such as a GPU). Each construct’s syntax for both C/C++ and Fortran is shown along with a description:
| C/C++ API | Fortran API | Description |
|---|---|---|
#pragma omp target [clauses] | !$omp target [clauses] | Transfers code and data to the device. |
#pragma omp target teams [clauses] | !$omp target teams [clauses] | Creates a league of teams on the device, executed by initial threads. |
#pragma omp target teams distribute | !$omp target teams distribute | Distributes iterations among team leaders on the device. |
#pragma omp target teams distribute parallel for | !$omp target teams distribute parallel do | Offloads code, distributes iterations, and executes in parallel on teams. |
#pragma omp target teams distribute parallel for simd | !$omp target teams distribute parallel do simd | Adds SIMD vectorization to parallelized team execution. |
targetdirective: Transfers execution from the host to the target device.target teamsdirective: Establishes a hierarchy of teams on the device, where each team has a single initial thread.- Combination directives (
target teams distribute parallel): These combine device offloading with team distribution and parallel execution, enabling efficient utilization of device resources.
Loop and Parallel Constructs¶
This table focuses on constructs that allow parallelization of loops and concurrent execution on the target device:
| C/C++ | Fortran | Description |
|---|---|---|
#pragma omp target parallel [clauses] | !$omp target parallel [clauses] | Creates a parallel team on the device. |
#pragma omp target parallel for | !$omp target parallel do | Parallelizes a loop on the device. |
#pragma omp target parallel loop | !$omp target parallel loop | Parallelizes and loops over iterations concurrently. |
#pragma omp target teams loop | !$omp target teams loop | Offloads and creates teams executing loop iterations. |
target paralleldirective: Creates parallel teams on the device for executing code blocks.parallel fororparallel loopdirectives: Parallelizes loops on the target device, allowing concurrent execution across loop iterations.teams loopdirective: Offloads loops to teams of threads on the device, supporting fine-grained parallelism in iterative calculations.
SIMD and Combined Constructs¶
The table highlights constructs that introduce SIMD (Single Instruction, Multiple Data) execution along with device offloading and parallelization:
| C/C++ | Fortran | Description |
|---|---|---|
#pragma omp target simd | !$omp target simd | Offloads and vectorizes loop for SIMD execution. |
#pragma omp target parallel for simd | !$omp target parallel do simd | Combines parallel execution with SIMD vectorization. |
#pragma omp target teams distribute simd | !$omp target teams distribute simd | Distributes work among teams with SIMD execution. |
#pragma omp target teams distribute parallel for simd | !$omp target teams distribute parallel do simd | Fully combines offloading, team distribution, parallelization, and SIMD. |
simddirective: Vectorizes loop iterations for SIMD execution, optimizing throughput by applying operations across multiple data points simultaneously.- Combined SIMD with
parallelandteams distribute: Enables fully optimized execution, combining offloading, team distribution, parallelization, and SIMD, providing the highest potential speedup on devices that support these features.
Explanation of Constructs and Usage¶
target parallel: Offloads code to the device and creates a team of threads to execute the region.target teams distribute parallel for: Combines thetarget,teams,distribute, andparallel forconstructs to distribute loop iterations across multiple teams, with each team executing its subset in parallel.simd: Thesimdconstruct vectorizes loop iterations for more efficient execution on hardware that supports SIMD lanes, such as GPUs. Used in combination withparallel forordistributeto achieve maximum throughput.
These constructs allow for flexible, hierarchical parallelism on heterogeneous hardware, making it easier to scale code across CPUs and accelerators. OpenMP Offloading's compute constructs enable fine-grained control over work distribution, data transfer, and SIMD execution, making it an ideal choice for high-performance applications on multi-threaded and multi-device architectures.