Using Cache and Unified Memory in OpenACC¶
Script
- "This article introduces two advanced memory management techniques in OpenACC: the cache directive and unified memory. These methods optimize memory access, reduce latency, and simplify the interaction between CPU and GPU memory, essential for performance in complex applications."
- "The OpenACC cache directive stores frequently accessed data in the GPU’s shared memory, reducing latency by keeping data close to GPU cores. This approach is beneficial for scenarios where certain data elements are reused multiple times, as it minimizes the need to access slower global memory."
- "This example uses cache(a[i:3]) to cache three elements of array a, improving access speed for these elements. By storing this data in shared memory, the code minimizes latency when reusing a[i], a[i+1], and a[i+2] in each loop iteration."
- "Unified memory creates a shared address space between CPU and GPU, allowing data to migrate automatically between host and device as needed. This approach simplifies memory management, as it removes the need for explicit data directives like copyin and copyout."
- "In this C/C++ example using unified memory, the independent clause tells the compiler there are no dependencies between loop iterations. Unified memory eliminates the need for data directives, as data transfers between CPU and GPU are handled automatically."
- "In Fortran, unified memory similarly removes the need for explicit data directives like copyin and copyout. Here, the kernels directive initiates parallel execution on the GPU, with data transfers managed by the unified memory model."
- "In summary, the cache directive improves performance by reducing memory latency for frequently accessed data, while unified memory simplifies code by handling data transfers automatically. Together, these features enable efficient memory management in OpenACC, enhancing both performance and ease of use for GPU applications."
This article discusses two advanced memory management features in OpenACC: the cache directive and unified memory. These techniques help improve performance by optimizing data access patterns between the host (CPU) and device (GPU) memory.
OpenACC cache Directive¶
The OpenACC cache directive is designed to store frequently accessed data in a GPU's shared memory, which has lower latency than global memory. By caching portions of an array, applications can reduce the time spent on memory accesses, especially in cases where some data elements are reused multiple times by threads in the GPU.
Caching can be applied to an entire array or to specific sections of an array, depending on the available shared memory. If the array section is too large for shared memory, the GPU will revert to loading from global memory, which can slow down performance. It is therefore recommended to cache smaller, frequently accessed portions of an array to maximize the performance benefits.
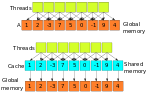 Figure 1: Illustration of cache concept
Figure 1: Illustration of cache concept
In Figure 1, an example demonstrates caching specific elements of an array in shared memory. Here, threads often need A(i-1), A(i), and A(i+1). Caching a 3-element section, A(i:3), helps each thread quickly access these values from shared memory rather than global memory, reducing memory access time.
Example of cache in C/C++¶
Below is an example of using the cache directive in C/C++ for a vector addition function. The function caches a 3-element section of the a array to improve access speed.
// Vector_Cache_OpenACC.c
void Vector_Addition(float *a, float *b, float *restrict c, int n)
{
#pragma acc kernels loop copyin(a[:n], b[0:n]) copyout(c[0:n])
for(int i = 0; i < n-2; i ++)
{
#pragma acc cache(a[i:3])
c[i] = a[i] + a[i+1] + a[i+2] + b[i];
}
}
cache(a[i:3])tells the compiler to store three elements of array a, starting from index i, in shared memory.- The cached elements are
a[i],a[i+1], anda[i+2], which are reused in each loop iteration.
This setup is beneficial for GPUs with limited shared memory. For more details, see the full example, Vector_Cache_OpenACC.c.
Example of cache in Fortran¶
Here’s the Fortran version of the vector addition function with the cache directive applied to a portion of array a.
subroutine Vector_Addition(a, b, c, n)
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
!$acc kernels loop copyin(a(1:n), b(1:n)) copyout(c(1:n))
do i = 1, n-2
!$acc cache(A(i:3))
c(i) = a(i) + a(i+1) + a(i+2) + b(i)
end do
!$acc end kernels
end subroutine Vector_Addition
cache(a(i:3)) caches the specified range of a within each loop iteration. The Fortran example is functionally similar to the C/C++ code above. See Vector_Cache_OpenACC.f90 for the complete code. Unified Memory in OpenACC¶
Unified memory, also known as managed memory, provides a unified address space shared between the CPU and GPU. This allows data to be automatically migrated between host and device, simplifying memory management. In OpenACC, unified memory is enabled using the managed compiler flag. When unified memory is used, explicit data clauses (copyin, copyout, etc.) become unnecessary as memory transfers are managed automatically by the system.
Unified memory is particularly useful for applications with complex memory access patterns or cases where data might need to be frequently accessed by both the host and device. This reduces the complexity of managing memory locations and transfers manually.
 Figure 2: Overview of Unified Memory
Figure 2: Overview of Unified Memory
Figure 2 illustrates how unified memory works, enabling seamless memory access across CPU and GPU. The managed memory model automatically migrates data as needed, maintaining consistency without requiring manual data directives in the code.
Unified Memory Example in C/C++¶
Below is an example of a vector addition function in C/C++ using unified memory. The managed flag enables unified memory, so we don’t need to specify data clauses. For more details, see the full example, Vector_Addition_Managed_OpenACC.c.
// Vector_Addition_Managed_OpenACC.c
void Vector_Addition(float *a, float *b, float *c, int n)
{
#pragma acc kernels loop independent
for(int i = 0; i < n; i ++)
{
c[i] = a[i] + b[i];
}
}
In this example:
- The
independentclause is used to inform the compiler that there are no dependencies between loop iterations, allowing more efficient execution. - The
restrictkeyword can be omitted as themanagedmemory model takes care of memory consistency.
To compile this code with unified memory enabled, use the following command:
nvc -fast -acc -gpu=cc80,managed -Minfo=all Vector_Addition_Managed_OpenACC.c
Unified Memory Example in Fortran¶
The unified memory concept in Fortran is similar. Here’s the Fortran version of the vector addition function using unified memory. In this case, we also omit the copy clauses. For more details, see the full example, Vector_Addition_Managed_OpenACC.f90.
subroutine Vector_Addition(a, b, c, n)
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
!$acc kernels loop
do i = 1, n
c(i) = a(i) + b(i)
end do
!$acc end kernels
end subroutine Vector_Addition
copyin and copyout clauses is enough when using unified memory. To enable unified memory in Fortran, compile the code with the managed flag: nvfortran -fast -acc -gpu=cc80,managed -Minfo=all Vector_Addition_Managed_OpenACC.f90
Summary¶
Using the cache directive and unified memory can greatly simplify memory management and improve performance in GPU applications:
cachedirective: Stores frequently accessed data in the GPU’s shared memory to reduce latency, which is beneficial in high-reuse scenarios.- Unified memory: Eliminates the need for explicit data management between CPU and GPU, allowing OpenACC to handle data migration automatically. This approach simplifies code while maintaining performance, especially for complex memory usage patterns.
- Both methods offer powerful ways to optimize data access, and each has its own strengths depending on the specific application requirements.