Computer Architecture¶
Parallel processing concepts existed even in the pre-electronic computing era in the 19th century. For instance, Babbage (Babbage’s analytical engine, 1910) considered parallel processing for speeding up the multiplication of two numbers by using his difference engine.
The Von Neumann architecture, illustrated in Figure 1 (a), established the foundation of sequential processing in high-speed computing. Despite its fast computation, it suffered from the Von Neumann bottleneck (Alan Huang, 1984) due to the limitation of I/O access to memory. Recent improvements have incorporated memory banks that allow parallel I/O to mitigate this bottleneck.
Parallelization can generally be achieved in two ways: vectorization within a single processor or multiprocessing across multiple processors. The performance of a computer is often measured by its ability to handle floating-point operations, as ranked by benchmarks like LINPACK (Jack J Dongarra et al., 1979), which assesses the time taken to solve dense linear equations.
 Figure 1: (a) The Von Neumann architecture; (b) Early dual-core Intel Xeon
Figure 1: (a) The Von Neumann architecture; (b) Early dual-core Intel Xeon
Multicore CPU¶
A multicore processor integrates two or more individual cores onto a single chip. In recent years, multicore CPUs have become increasingly popular, with manufacturers continually increasing the number of cores per chip. Figure 1 (b) shows a dual-core Intel Xeon processor from 2005. Modern multicore CPUs have individual L2 caches for each core and a shared L3 cache across cores. A memory controller manages access to the memory banks in DRAM.
According to Flynn’s taxonomy, computer architectures can be classified as:
- SISD (Single Instruction Single Data): A simple, sequential model.
- SIMD (Single Instruction Multiple Data): Executes the same instruction on multiple data, achieving data-level parallelism.
- MISD (Multiple Instruction Single Data): Rarely used, as it is difficult to map general programs to this architecture.
- MIMD (Multiple Instruction Multiple Data): Allows multiple instructions on multiple data, ideal for multicore CPUs that support thread-level parallelism.
 Figure 2: (a) Memory hierarchy; (b) SIMD model
Figure 2: (a) Memory hierarchy; (b) SIMD model
The memory hierarchy in CPUs is designed to optimize access times. On-chip caches provide rapid access to frequently used data, while off-chip memory offers larger but slower storage. Figure 2 (a) illustrates a typical memory hierarchy, with CPU cores accessing caches first before main memory.
Shared Memory Architectures¶
In shared-memory architectures, multiple processors access a shared memory space. These architectures can be further categorized as:
- Uniform Memory Access (UMA): Also known as Symmetric Multi-Processing (SMP), where memory access time is uniform across all processors.
- Non-Uniform Memory Access (NUMA): Memory is divided into segments for each processor, with faster access to local segments and slower access to remote segments.
- Distributed Shared Memory: Combines elements of both UMA and NUMA, allowing processors to access distributed memory with consistency maintained through a memory management unit.
 Figure 3: Shared memory architectures
Figure 3: Shared memory architectures
Figure 3 shows examples of these architectures, highlighting the organization and data access patterns of each.
Distributed Memory Architectures¶
Modern supercomputers are commonly based on distributed memory architecture, where compute nodes are linked via high-speed networks. Each node has its processor and memory, and data is exchanged between nodes using message-passing protocols. This architecture relies heavily on the network topology and programming model for efficiency.
Popular network topologies include 3D Torus, Fat-Tree, and Dragonfly. Among these, Fat-Tree topology is widely used due to its versatility and high bandwidth. Figure 4 illustrates a distributed memory architecture, where each node communicates with others over a network.
Programming models like MPI (Message Passing Interface) support distributed memory architectures by providing a standardized way for processes to communicate. Libraries such as MVAPICH2, OpenMPI, MPICH, and Intel MPI allow developers to write parallel applications that scale across large supercomputers. While these libraries offer similar functionality, performance may vary based on the network and application design.
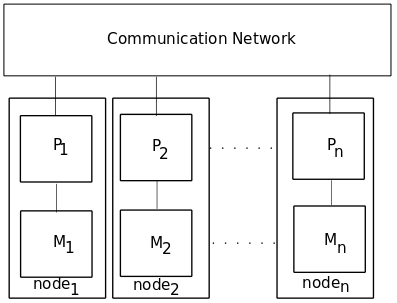 Figure 4: Distributed memory architecture
Figure 4: Distributed memory architecture